自從有搜索引擎以來,就有人不斷研究搜索引擎的排名機制,進而尋找搜索引擎排名的技術和邏輯漏洞,來快速提升自己網站的搜索排名,並且獲得流量和收益。也就是說自從有搜索引擎以來,作弊就沒有停止過。為了保證呈獻給用戶的搜索結果質量,發掘真正內容優質、用戶體驗最佳的網頁,反作弊一直都是搜索引擎研究的重要課題,但是搜索引擎一直處於被動應對地位,經常是發現搜索結果被作弊網頁攻陷了,才去研究相應的反作弊對策和算法。那麼搜索引擎在反作弊的過程中主要是如何操作的呢?真的會像外界猜測的那樣有那麼多的人工干預嗎?
反作弊算法在搜索引擎的架構中過濾也是很重要的一環,在Spider抓取部分會過濾掉重復和垃圾頁面,在進行排序和呈現時同樣還會進行一次過濾,來保證搜索結果的質量。反作弊就是過濾環節中的主要組成部分。當下搜索引擎排名的重要參考因素主要有內容、鏈接、網站權重和用戶體驗,所以作弊也一般是從這幾方面入手。第12章會詳細討論一下常見的作弊手法,這裡主要來討論一下搜索引擎是如何進行反作弊的,反作弊過程中是否會出現誤傷,以及站長和SEO人員應該如何避免被搜索引擎誤傷。
雖然搜索引擎針對每種作弊行為所做的反作弊動作和算法各不相同,但是大體上還是有一定規律可循的。搜索引擎會利用黑白名單和作弊特征研究兩方面進行反作弊算法升級。
黑白名單
搜索引擎會根據網站內容的質量、權重、品牌建立白名單,也會找出明顯作弊嚴重的網站建立黑名單。搜索引擎會認為白名單中網站所推薦的網站都是好的、健康的網站,含有黑名單中網站鏈接的網站可能會存在某種問題。
如圖2-24所示,鏈向白名單中網站的網站不一定是健康的,同時黑名單中網站鏈向的網站也不一定是不健康的。但是有多個白名單網站鏈向同一個網站,那麼這個網站就很可能是健康的。同一個網站鏈向了多個黑名單中的網站,就可以把其認定為不健康的網站。
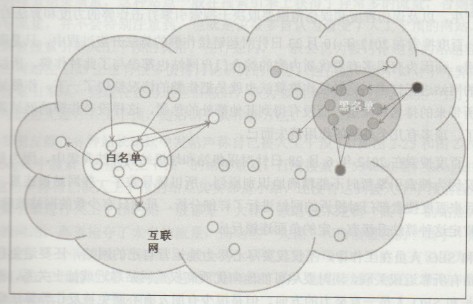
圖 2-24 黑白名單示意圖
- 上一頁:百度綠蘿算法上線公告2013年2月
- 下一頁:從百度指數看熱門事件炒作的威力